
I’ve recently started working on a new game engine and, since I have no restraint, task zero was writing custom memory allocators. C++’s built in malloc() and new are great tools for getting a hold of raw memory, but they don’t leave any room for customization or optimization based on how that memory is utilized. Custom allocators perform the same job in a context-aware way, which provides the opportunity to take shortcuts malloc() and new never could.

The source code for the engine and all the allocators discussed can be found here. If you’re looking for a library to get you started, check out foonathan’s memory allocators.
The Allocator Interface
The interface I decided on for the allocator system was pretty simple:
class Allocator
{
public:
virtual void* Allocate(size_t size, size_t alignment) = 0;
virtual void Free(void* memory) = 0;
template<class T>
void* AllocateType();
};
The controlling ideas here is that users interact with allocators through stateful instances, which provides more flexibility when chaining or changing allocators out at runtime. AllocateType<T> is a handy template function that simply calls Allocate() with arguments sizeof(T) and alignof(T).
This interface was the first thing I wrote, and was inspired by an amalgam of sources that provided some great insights:
In addition to this interface, there’s some golden rules that each allocator must follow:

The Unmanaged Allocator
This allocator is about as simple as possible. It’s just a thin wrapper over malloc().
class UnmanagedAllocator : public Allocator
{
public:
void* Allocate(size_t size, size_t alignment = alignof(max_align_t))
{
return malloc(size);
}
void Free(void* memory)
{
free(memory);
}
};
In case you were wondering malloc() allocates virtual memory. You could ask it for more memory than there is ram in your machine.
Allocator Tools
With the first allocator done, we can also start building tools that provide access to the system.
The Memory Sytem
Here’s a simple structure that provides access to the unmanaged allocator across the engine:
class MemorySystem
{
public:
static Allocator* GetUnmanagedAllocator()
{
static UnmanagedAllocator s_Allocator;
return &s_Allocator;
}
};
Now any caller can include MemorySystem.hpp and get access to a memory allocator. Later, this class can be extended to allow the engine to initialize more advanced allocators, and reserve a configurable amount of memory at startup. For now though this Unmanaged Allocator will be valid for the duration of the program’s life, and will be destroyed automatically after the program terminates.
Overriding new and delete
Now that we have an allocator and a means of accessing it, the next step in getting a handle on your system’s memory allocations is to override the global new and delete operators.
You can do so by adding the following in any .cpp file. At link time, the linker will find these definitions and use them to replace the defaults everywhere in your program.
[[nodiscard]] void* operator new(size_t num_bytes) noexcept(false)
{
return MemorySystem::GetUnmanagedAllocator()->Allocate(num_bytes);
}
void operator delete(void* memory) noexcept
{
MemorySystem::GetUnmanagedAllocator()->Free(memory);
}
This means calls to operator new() and operator delete() will now be forwarded to our allocator. This is also why the UnmanagedAllocator does not track memory allocations. Since the destruction order of the MemorySystem is out of our control, if any other statically allocated object calls delete in it’s destructor the program will crash. This is a side effect of the static initialization order fiasco, and in this context there’s not much we can do about it.
Memory Alignment
For the remaining allocators, it’s critical to understand the importance of memory alignment. Jonathan Rentzsch from IBM has an amazing rundown of everything you need to know. I highly suggest you give it a glance.
The short of it is that CPUs reads memory in chunks. If you don’t respect that behavior, depending on your hardware:
When memory allocations are aligned, all the data can be read with the minimum number of memory accesses. Unaligned data can straddle two memory accesses, and require the processor to do some extra work to stitch it together. These extra operations are always costly, and some processors may just refuse to to do them.
Calculating alignment
To get the alignment requirement for any type in C++ you can use the alignof() operator.
Here are the rules for what that operator returns:
Every data object has an alignment-requirement. The alignment-requirement for all data except structures, unions, and arrays is either the size of the object or the current packing size […]. For structures, unions, and arrays, the alignment-requirement is the largest alignment-requirement of its members. Every object is allocated an offset so that:
offset % alignment-requirement == 0
For more information on how structures are padded to enforce alignment requirements, see here.
Given the alignment requirement of the type and the memory address, we can calculate how far that address is from being aligned like so:
uintptr_t GetAlignmentOffset(size_t align_of, const void* const ptr)
{
// Note: m % n = m & (n-1) if n is a power of two
// Fun fact: Alignment requirements are always a power of two
return (uintptr_t)(ptr) & (align_of - 1);
}
To get the next aligned address for a type given some starting memory address, we can calculate an adjustment value:
uintptr_t GetAlignmentAdjustment(size_t align_of, const void* const ptr)
{
auto offset = GetAlignmentOffset(align_of, ptr);
// If the address is already aligned, we don't need any adjustment
if (offset == 0) {
return 0;
}
auto adjustment = align_of - offset;
return adjustment;
}
Adding that adjustment value to the memory address yields the next aligned address.
Linear Allocators
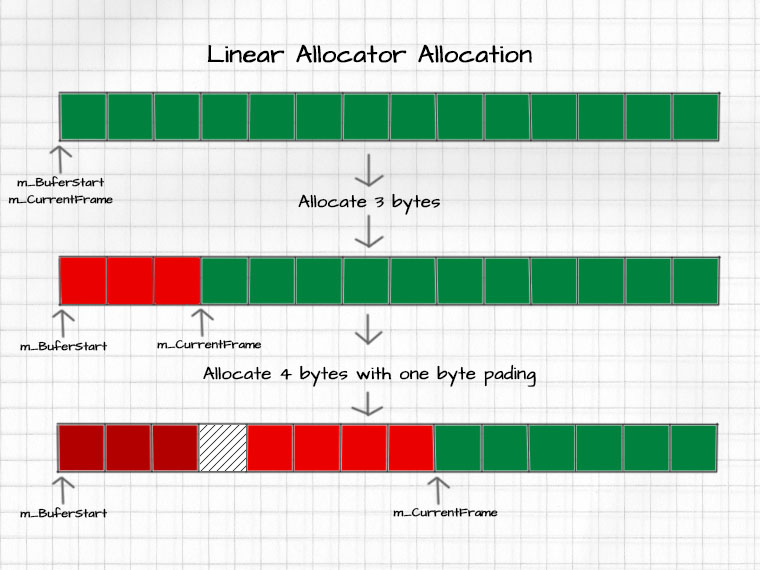
Linear allocators are extremely simple, performant, and memory efficient. They operate by maintaining a pointer to the start of their buffer, and a pointer to the first free memory address. Allocations bump the free space pointer forward, and individual Frees are disallowed. Instead, to reclaim memory the free space pointer is simply moved back to the start of the buffer.
Allocations
Allocations bump the free pointer forward by exactly allocation_size + alignment_padding bytes. The allocator returns a pointer the first byte after padding.
Frees
To reclaim memory from a linear allocator you can call Reset(). Reset moves the free pointer back to the start of the buffer, allowing the old data to be overwritten by new allocations. It doesn’t actually release the memory back to the operating system until the allocator is destroyed.
Linear Allocators cannot free individual allocations (and in the Screwjank Engine they’ll assert(false) if you try).
Implementation
LinearAllocator.hpp
LinearAllocator.cpp
Stack Allocators
Like linear allocators, stack allocators trade flexibility for speed — albeit in a less extreme way. Stack allocators treat allocations and deallocations as push and pop operations, which means allocations must be released in a LIFO (last-in first-out) order.
Internally, stack allocators maintain:
- A pointer to the start of their buffer
- A pointer to the first free byte in their buffer
- A pointer to the most recent allocation header
Allocations
For every allocation stack allocators move an offset pointer into their buffer forward by the number of bytes requested, plus some extra amount to account for the allocation header and padding.
The allocation headers contain the metadata necessary to unwind the stack:
struct StackAllocatorHeader
{
/** Pointer to the previous allocation */
StackAllocatorHeader* PreviousHeader;
/** Number of padding bytes inserted before the header for alignment */
size_t HeaderOffset;
}
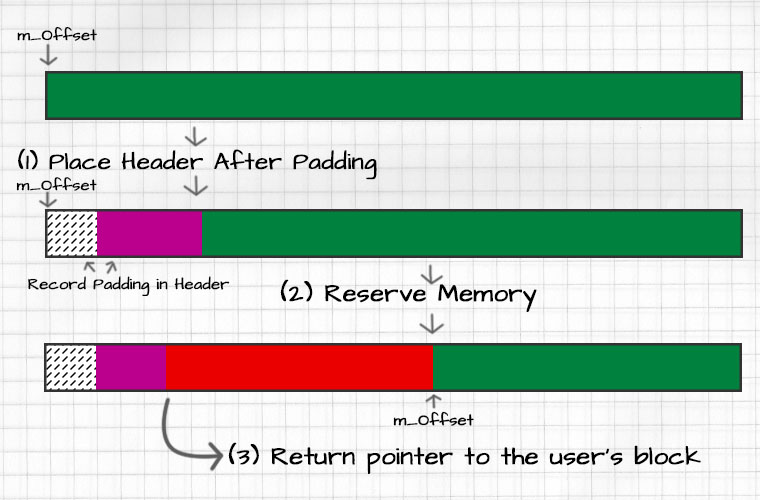
When allocating with header for any allocator we need to ensure:
- The header and user payload are right next to each other.
- Both data segments reside at an address that satisfies their alignment requirements.
You can find an address that satisfies these conditions by:
-
Assuming the earliest possible payload address is:
m_Offset + sizeof(StackAllocationHeader) -
Determining the strictest alignment requirement between the header and the user data:
max(requested_alignment, alignof(StackAllocatorHeader)) -
Finding how many bytes we need to adjust the payload address from step 1 by to satisfy the alignment requirement from step 2:
GetAlignmentAdjustment(strict_alignment, first_payload_address)
This means the allocation header can be placed at uintptr_t(m_Offset) + adjustment, with the user data atuintptr_t(m_Offset) + adjustment + sizeof(StackAllocatorHeader).
Now that we know where everything needs to go — assuming there’s enough space in the buffer — we can:
- Place the header in the buffer and mark it as the current allocation header.
- Update the stack allocator’s offset to point to the first byte after the user’s data
- Return a pointer to the user’s block
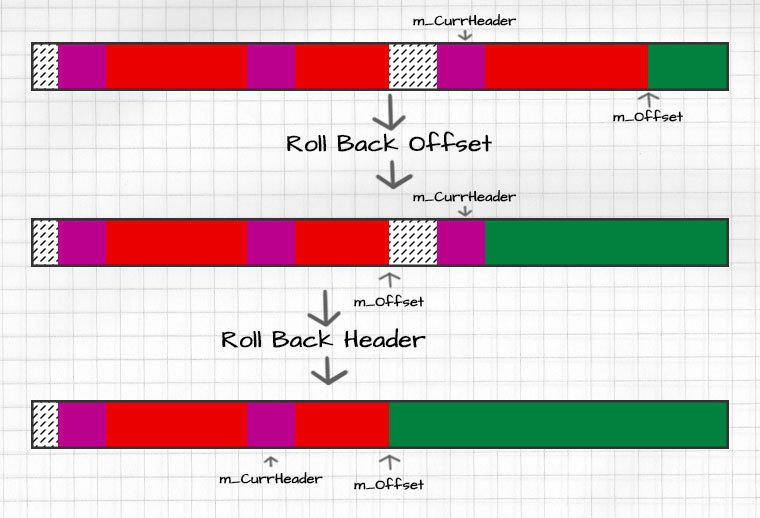
Frees
Freeing data from the stack allocator is also fairly simple. Since this most recent allocation header is tracked by the allocator the free operation is simply:
-
Roll back
m_Offsetto the fist free byte after the last allocation:
This is the address of the current header minus the offset that header has stored. -
Update the allocator’s current header to: </br>
current_header->PreviousHeader
If the user instead called Free() with a memory address instead of pop, you simply need to verify that address is the top block.
Implementation
StackAllocator.hpp
StackAllocator.cpp
Pool Allocators
Pool allocators are general purpose allocators capable of allocating and freeing data in any order, as long as that data is lesser than or equal in size to the allocator’s block size. Every allocation of any valid size will reserve one block’s worth of memory. When used for allocations that are equal to (or at least very close to) the block, pool allocators offer huge gains for memory utilization and keep memory fragmentation in check.
Internally pool allocators maintain:
- A pointer to the start of their buffer
- A linked list of free blocks, constructed in the buffer
- A pointer the the head of that linked list
On construction pool allocators split their data buffer into fixed-sized blocks, with and construct a linked list with nodes placed at the beginning of every block. When a block is allocated, the header removed from the linked list and it’s data is overwritten. The header is re-inserted and re-added on free.
In the Screwjank Engine pool allocators use a template parameter to define their blocks size. Doing so allows compile-time validation that the blocks are large enough to hold the free list nodes.
template <size_t kBlockSize>
class PoolAllocator
{
PoolAllocator(size_t num_blocks, Allocator* backing_allocator);
~PoolAllocator();
...
};
Initialization
After construction every block in the pool allocator contains a FreeBlock structure:
struct FreeBlock
{
FreeBlock* Next;
};
The struct is a stylistic choice to make others less sad when they read your code. You can instead chain void pointers together to construct the list if you hate your fellow man.
There’s no such thing as a zero-cost abstraction. Since PoolAllocator is templated and FreeBlock is a private type defined inside it, every specialization of PoolAllocator actually results in another type PoolAllocator<T>::FreeBlock being compiled. The cost here is negligible but not non-existent.
After acquiring a data buffer it can be split like into blocks like so:
PoolAllocator<T>::PoolAllocator(size_t num_blocks,
Allocator* backing_allocator)
{
...
// Create first free block at start of buffer
m_FreeListHead = new (m_BufferStart) FreeBlock {nullptr};
FreeBlock* curr_block = m_FreeListHead;
uintptr_t curr_block_address = (uintptr_t)m_BufferStart;
// Build free list in the buffer
for (size_t i = 1; i < num_blocks; i++) {
// Calculate the block address of the next block
curr_block_address += kBlockSize;
// Create new free-list block
curr_block->Next = new ((void*)curr_block_address) FreeBlock();
// Move the curr block forward
curr_block = curr_block->Next;
}
}
Allocation
Allocation simply returns the pointer of the first free block, and removes it from the list:
template <size_t kBlockSize>
inline void* PoolAllocator<kBlockSize>::Allocate(const size_t size,
const size_t alignment)
{
...
// Take the first available free block
auto free_block = m_FreeListHead;
...
// Remove the free block from the free list
m_FreeListHead = m_FreeListHead->Next;
...
return (void*)(free_block);
}
It’s not necessary to account for padding with pool allocators, since (with the exception of over-aligned types) alignof(T) <= sizeof(T). The memory address of each free block an alignment requirement of alignof(kBlockSize), so any data that fits in the block will have an equal or weaker alignment requirement.
Frees
The free operation simply places a FreeBlock back into the buffer, and places the block at the head of the free list:
template <size_t kBlockSize>
inline void PoolAllocator<kBlockSize>::Free(void* memory)
{
...
// Place a free-list node into the block
auto new_block = new (block_address) FreeBlock {m_FreeListHead};
// Push block onto head of free list
m_FreeListHead = new_block;
...
}
Implementation
PoolAllocator.hpp
PoolAllocator.cpp
Free List Allocators
Free list allocators can serve arbitrarily sized allocations without imposing restrictions on when that memory can be released. They’re highly suitable as general purpose allocators, but they tread close to the same problems malloc() faces. In fact, you can implement malloc as a free list allocator.
Like pool allocators, free list allocators maintain an iterable record of which memory blocks are free. When appropriate allocations can split large blocks into smaller ones, and frees and can coalesce released blocks back into their neighbors.
Varying block sizes means selecting a block is now non-trivial. Therefore, we’re forced to search the free list for a “good” block. The definition of good depends on your allocation strategy. The following are some of the most common options:
| First Fit | Search the free-list and terminate as soon as you find a free block |
| Best Fit | Search the free-list exhaustively and chose the smallest block that can accommodate your allocation |
| Worst Fit | Search the free-list exhaustively and chose the largest block that can accommodate your allocation |
First fit is computationally the fastest, and is the one I’ve decided to use in my implementation. However, all three methods have different pathological allocation patterns (see ~slide 9 here), so the best option is really to expose the choice to the allocator’s user. The Scewjank Engine doesn’t expose that option yet, and defaults to using a first-fit strategy.
Initialization
During initialization the FreeListAllocator marks the entire buffer as a single free block. At the beginning of the buffer we place the following structure and mark it as the head of the free list:
struct FreeBlock
{
size_t Size;
FreeBlock* Previous;
FreeBlock* Next;
};
As you can see above, the free list for this implementation is a doubly-linked list. This forces all allocation and deallocation strategies to be worst case O(n), where n is the number of blocks in the free list. This is far from optimal, and most implementations use a Red-Black tree sorted by block size instead to lower the cost of searching the free list to O(log(n)).
In addition to the free list, you can also calculate the some compile-time constants to make the logic of determining when blocks split simpler:
static constexpr size_t kMinBlockSize =
std::max(sizeof(FreeBlock), sizeof(AllocationHeader) + 1);
static constexpr size_t kMaxMetadataAlignment =
std::max(alignof(FreeBlock), alignof(AllocationHeader));
Allocation
The steps for allocating from a free list allocator are as follows:
- Find a free block that satisfies your allocation strategy
- Remove the block from the free list, and calculate the allocation data
- Attempt to split a new free block from the discovered block
- If successful, update the allocation header
void* FreeListAllocator::Allocate(const size_t size,
const size_t alignment)
{
// Search the free list, and return the most suitable free block
// and the padding required to use it
auto free_list_search_result = FindFreeBlock(size, alignment);
FreeBlock* best_fit_block = free_list_search_result.first;
size_t header_padding = free_list_search_result.second;
...
// Remove block from the free list
RemoveFreeBlock(best_fit_block);
// Get a copy of the current block info before it is overwritten
FreeBlock old_block_info = *best_fit_block;
// Calculate allocation information
void* header_address =
(void*)((uintptr_t)best_fit_block + header_padding);
void* payload_address =
(void*)((uintptr_t)header_address + sizeof(AllocationHeader));
auto payload_space =
old_block_info.Size - sizeof(AllocationHeader) - header_padding;
...
// Place the header into memory just before the user's data
// This operation overwrites the data pointed to by best_fit_block
auto header =
new (header_address) AllocationHeader(header_padding, payload_space);
// Calculate unused space and attempt to make a new free block
uintptr_t payload_end = (uintptr_t)payload_address + size;
uintptr_t block_end = uintptr_t(payload_address) + payload_space;
// Padding required to align a new free block after the end of
// the user payload
auto new_block_adjustment =
GetAlignmentAdjustment(alignof(FreeBlock), (void*)payload_end);
// Padding bytes for the new block would be left at the end
// of the current block
auto unused_space = block_end - (payload_end + new_block_adjustment);
if (unused_space >= kMinBlockSize) {
// Remove unused_space from the allocation
// header's representation of the block
header->Size -= unused_space;
// Place a FreeBlock into the buffer after the user's payload
void* new_block_address =
(void*)(payload_end + new_block_adjustment);
FreeBlock* new_block =
new (new_block_address) FreeBlock(unused_space);
// Insert the new block into the free list
AddFreeBlock(new_block);
}
...
return payload_address;
}
Block Splitting
To split a block there needs to be enough space left-over after the user’s data to accommodate the FreeBlock and AllocationHeader structures at different points in time. The following diagram assumes sizeof(FreeBlock) > sizeof(AllocationHeader).
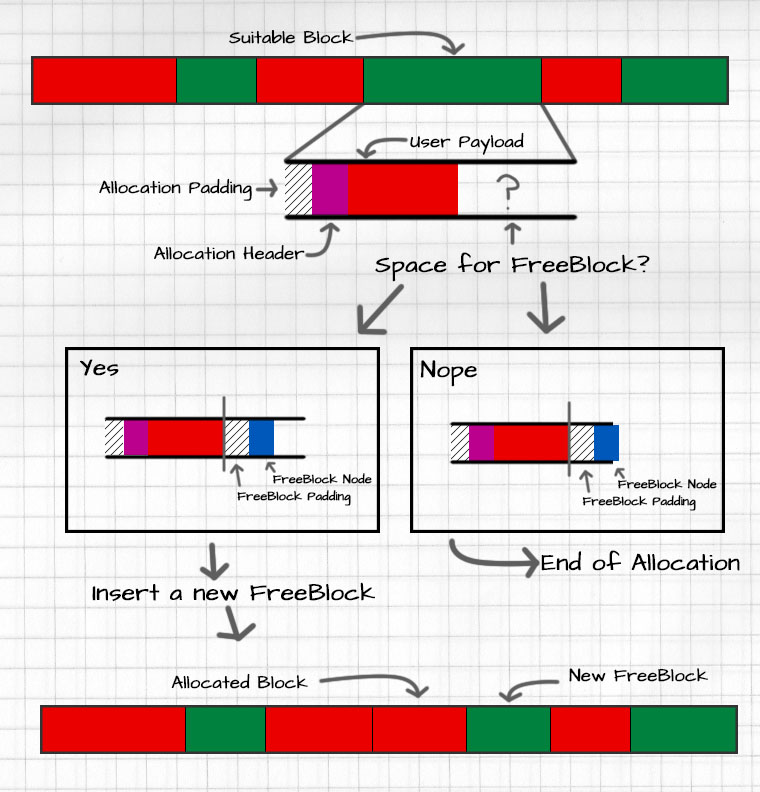
Block Insertion
When inserting blocks into the free list, you have two options:
- Always push the block onto the front of the list
- Scan the list and place the block such that all the addresses are sorted in ascending order.
Option one reduces the runtime of the insertion operation to O(1), but increases the runtime of coalescing blocks to O(n). In large buffers runtime for searching the free list can be severely impacted. The effectively random jumps into the buffer can skip across cache lines and cause cache misses.
Option two forces the runtime of block insertion to be O(n), but reduces the cost of block coalescion to O(1). Since the address of every element in the list is sequential, cache misses happen less frequently with large buffers.
Frees
To free from a free list allocator:
- Recover the allocation header to find:
- The real start of the block, which may be before the header’s address due to padding.
- The size of the block being released.
- Construct a new free list node
- Insert the new into the free list
- Attempt to coalesce the new node with its neighbors
void FreeListAllocator::Free(void* memory)
{
...
AllocationHeader* block_header =
(AllocationHeader*)((uintptr_t)memory - sizeof(AllocationHeader));
// Extract header info
auto block_size =
block_header->Padding + block_header->Size + sizeof(AllocationHeader);
void* block_start =
(void*)((uintptr_t)block_header - block_header->Padding);
...
FreeBlock* new_block = new (block_start) FreeBlock(block_size);
AddFreeBlock(new_block);
}
Block Coalescion
After a block has been inserted into the free list, we can attempt to merge it with it’s neighbors:
void FreeListAllocator::AttemptCoalesceBlock(FreeBlock* block)
{
// Attempt to coalesce with left neighbor,
// moving block pointer back if necessary
if (block->Previous != nullptr) {
uintptr_t left_end =
(uintptr_t)block->Previous + block->Previous->Size;
// If this block starts exactly where the
// previous block ends, coalesce
if ((uintptr_t)block == left_end) {
block->Previous->Next = block->Next;
if (block->Next != nullptr) {
block->Next->Previous = block->Previous;
}
block->Previous->Size += block->Size;
block = block->Previous;
}
}
// Attempt to coalesce with right neighbor
if (block->Next != nullptr) {
uintptr_t block_end = (uintptr_t)block + block->Size;
// If the end of this block is the start of the next block, coalesce
if (block_end == (uintptr_t)block->Next) {
block->Size += block->Next->Size;
block->Next = block->Next->Next;
if (block->Next != nullptr) {
block->Next->Previous = block;
}
}
}
}
Implementation
FreeListAllocator.hpp
FreeListAllocator.cpp
Proxy Allocator
Proxy allocators are adapters for other allocators. They simply forward all of their operations to a backing allocator, and maintain their own tracking data. They’re super useful for situations in which you want multiple systems to share an allocator instance, but keep separate tabs on each system’s memory usage.
They’re also super easy to implement.
Implementation
ProxyAllocator.hpp
ProxyAllocator.cpp
Conclusions
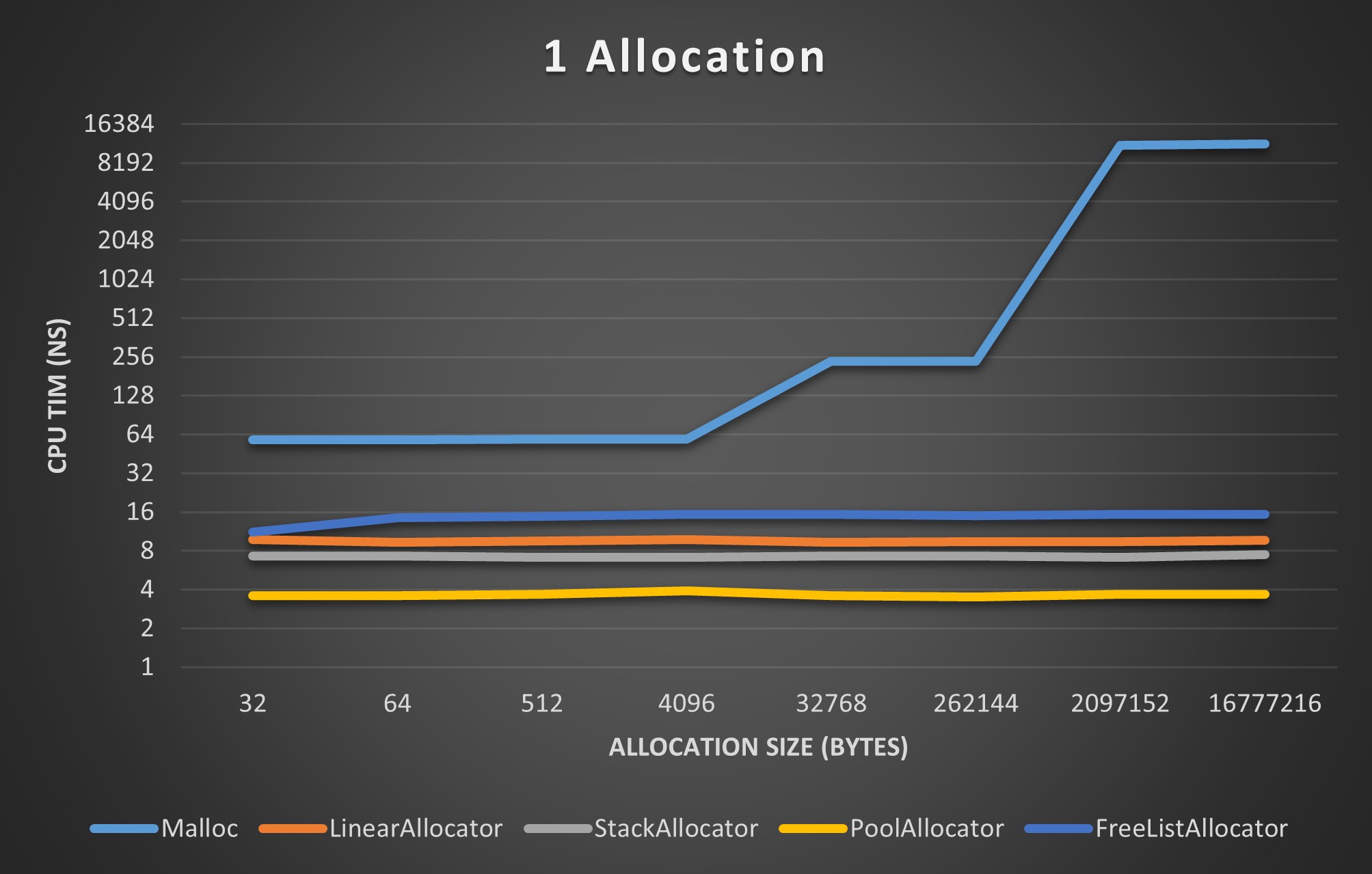
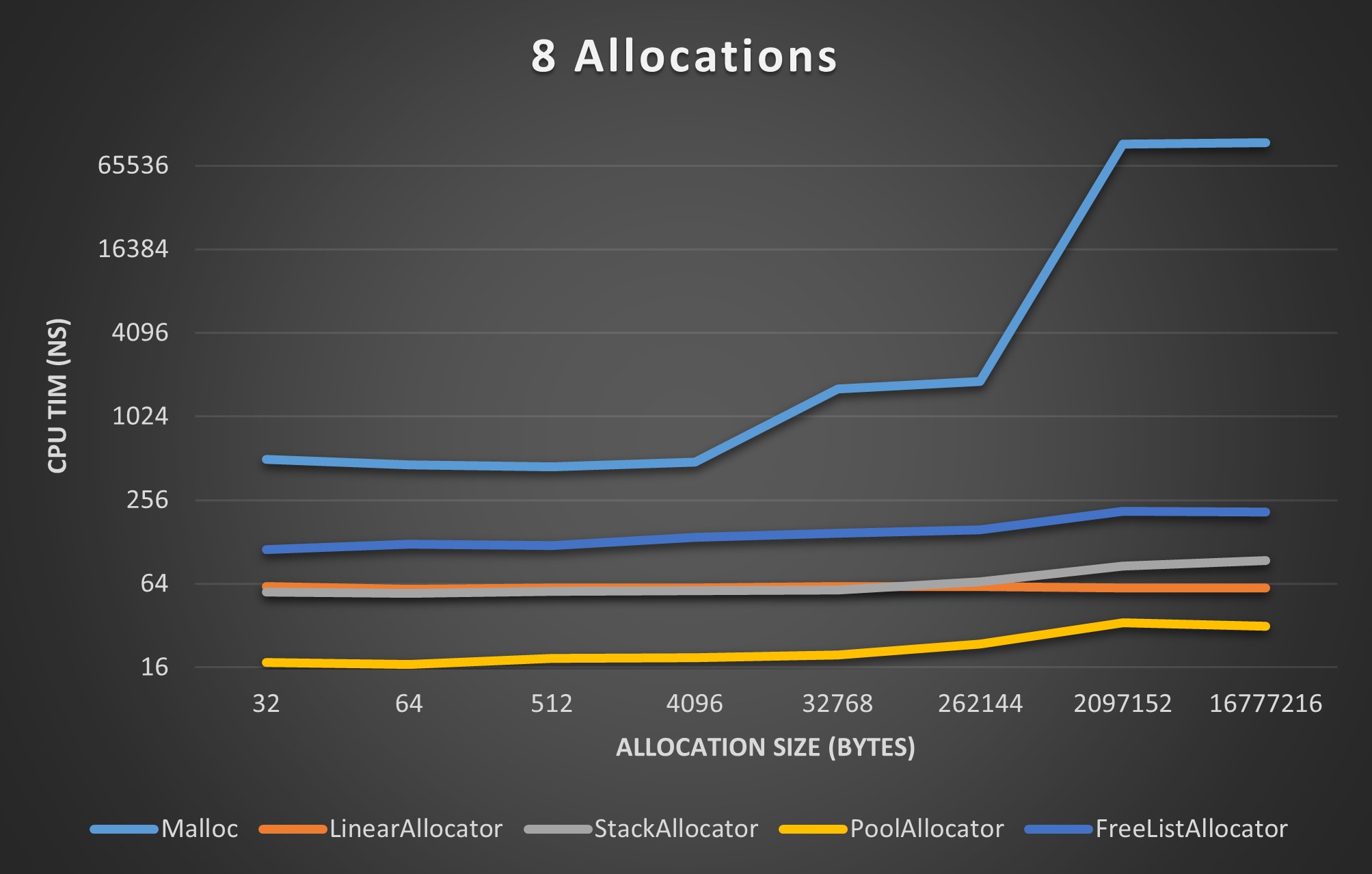
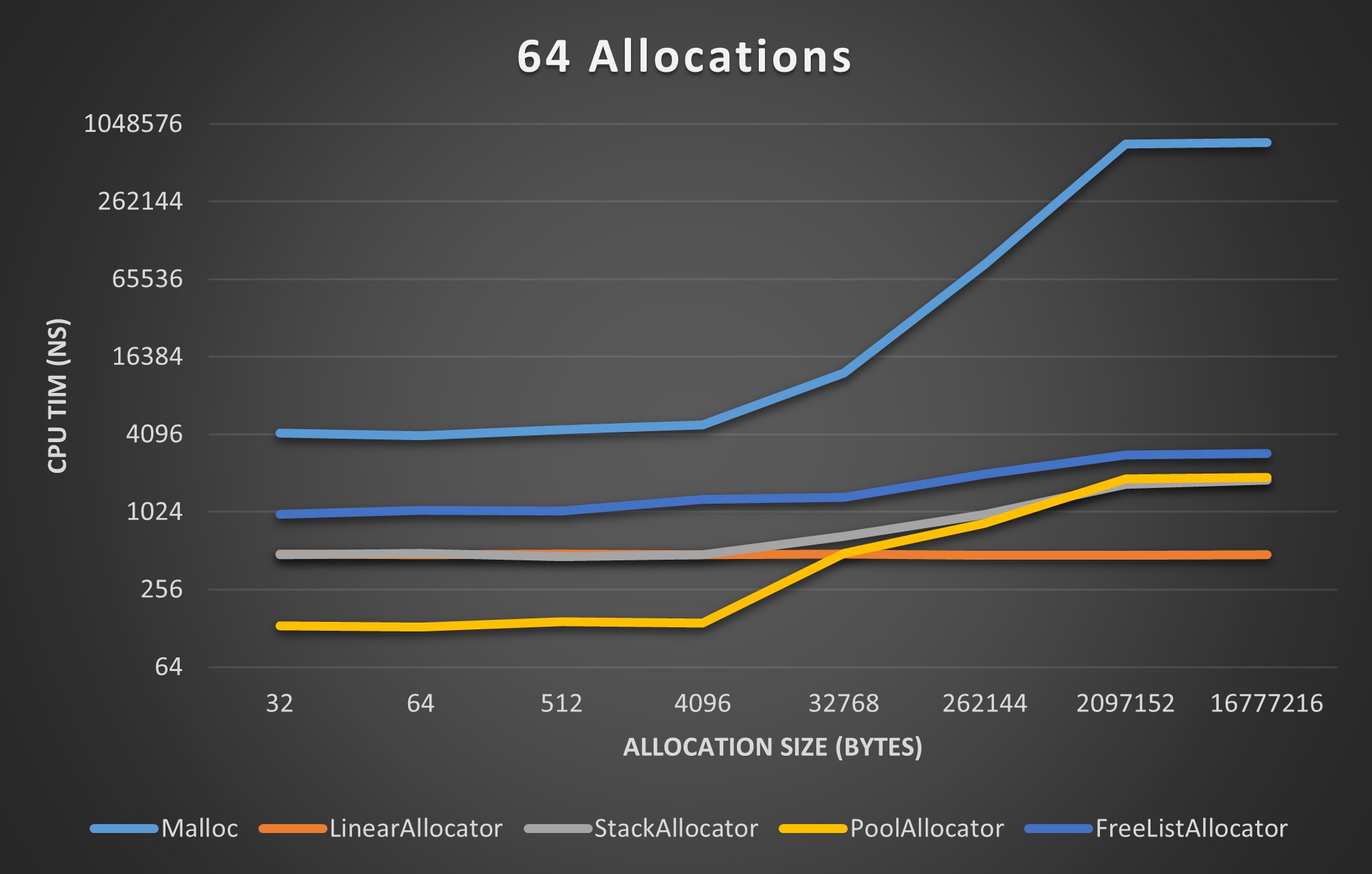
I’d like to end this post with some benchmarks that hopefully help convey why I put myself through this. These benchmarks are not exhaustive, but they provide a rough estimate of each allocator’s performance.
Each of the following benchmarks compares plots the CPU time (in nanoseconds) each allocator used to perform some number of allocations of the size specified on the horizontal axis. Allocation sizes ranged from 32 Bytes to 16 Mebibytes.
Single Allocation Benchmark
8 Allocation Benchmark
64 Allocation Benchmark
256 Allocation Benchmark
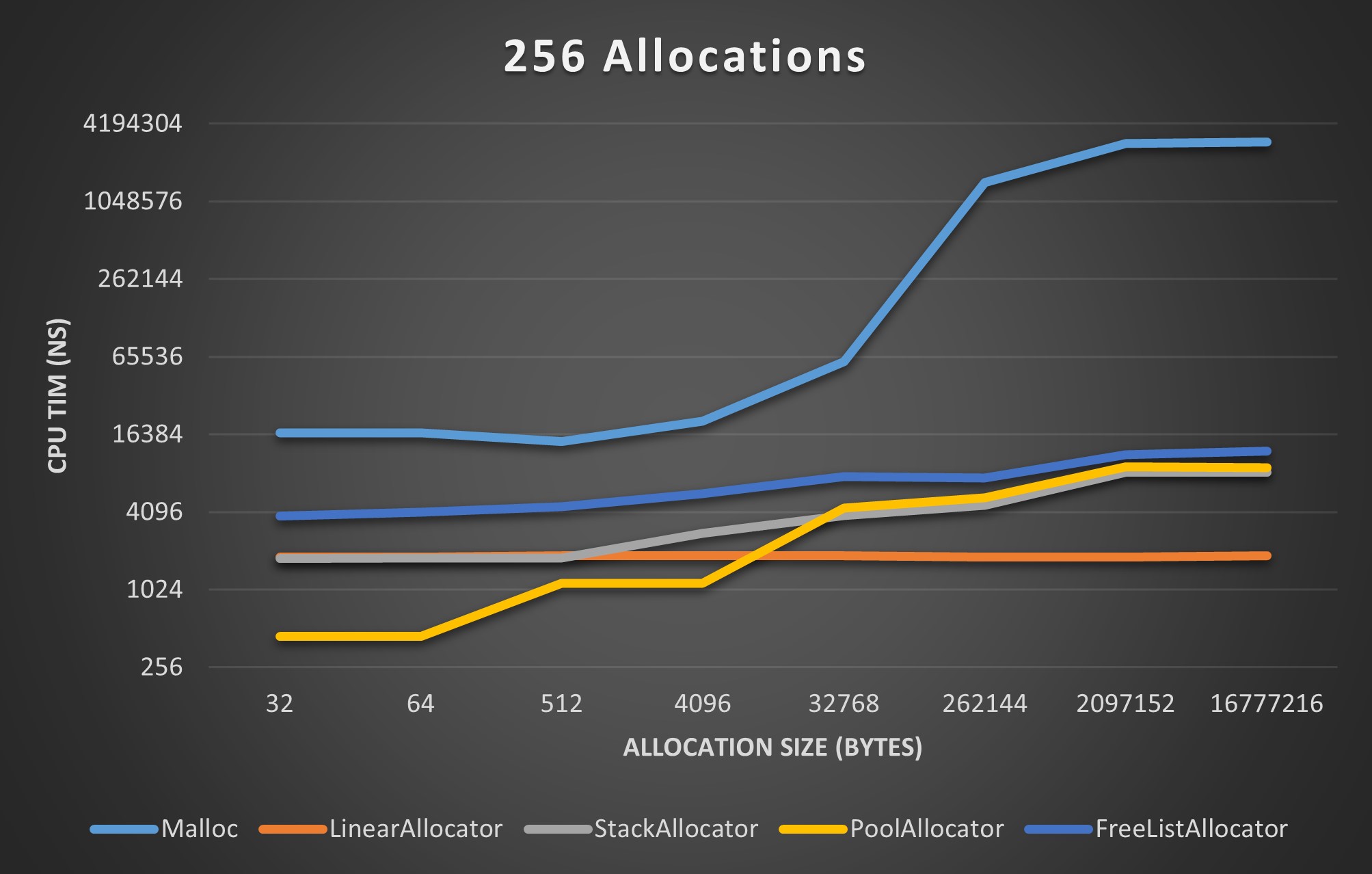
If you’d like to test it out for yourself, here is a link to the code used to generate the benchmark data above.